
In Brief
- The InsurTech Evolution: Modern insurance platforms have evolved from clunky, transactional portals into dynamic, AI-driven financial ecosystems that prioritize proactive risk mitigation over reactive payouts.
- Architecture Paradigms: Building a high-performance insurance application requires a secure, multi-layered architecture featuring microservices, event-driven processing for claims, and ultra-secure API integrations.
- Core Technology Drivers: Scalability and trust in 2026 depend on cross-platform mobile frameworks, real-time telematics ingestion engines, automated document parsing, and immutable transaction histories.
- The Claims Bottleneck: Success rests on moving away from manual adjustments and investing in automated, AI-powered Claims processing pipelines that slash cycle times from weeks to minutes.
- Security & Compliance: Engineering teams must architect absolute data sovereignty, end-to-end cryptographic encryption layers, and localized regulatory compliance modules directly into the data path.
- Strategic Engineering Advantage: Organizations that deploy modular microservices, robust caching layers, and predictable offline data sync mechanisms will capture superior retention and dominate the modern digital risk market.
There is currently a massive technological disruption in the insurance industry. The current generation of consumers and corporate clients would not tolerate slow processes, paper-based insurance workflows, and weeks-long processes of claims handling. Similar to what happened when instant communication networks began disrupting physical communities, the modern mobile apps are changing the way consumers and businesses evaluate risks and communicate with insurance carriers.
A contemporary development of a modern digital insurance application is defined by the need for a key shift in technology from traditional silo-based software products to integrated and rich-data InsurTech platforms. Today, the world-class insurance application needs to be able to handle automated KYC checks, instant customization of the policy, and multi-channel communication all the way through telematics processing with the help of IoT devices and OCR to automate document handling.
Designing a reliable insurance application is much more than designing a simple database wrapper that will contain a few web-based form pages. The development of a reliable insurance app requires building a state-of-the-art cloud-based platform capable of managing heavy writing operations, handling real-time calculations of the dynamic pricing model, routing secured patient or property assets, and properly integrating with old-school legacy back-end systems.
Why Modern InsurTech Systems Have Rapidly Grown
There is one very important reason why modern insurance technologies are rapidly growing they provide an opportunity to offer highly targeted risk coverage without any bureaucracy. In the past, buying an insurance policy and making claims required people to go through the cumbersome process of interacting with phone menus, insurance agents, and various regional offices.
With new systems, this problem can easily be overcome thanks to real-time data received from connected devices. For instance, car telematics, industrial IoT sensors, and wearable fitness trackers can provide information that can be used by the system to determine personal risk coverage. Now users can buy customized micro-insurance policies, change the coverage metrics instantly based on actual data, and upload pictures of damage right from the place of the incident.
Complete Guide to Insurance App Development
Structural Planning and Core Architecture Blueprints
You cannot begin writing code for an enterprise-grade insurance ecosystem without first establishing a highly structured and scalable architectural blueprint. An insurance platform functions on a complex, nested data model where transactional accuracy, data isolation, and auditability are non-negotiable.
To prevent performance degradation and maintain clean data boundaries, the architecture must be divided into explicit functional layers:
- Omni-Channel UI Layer: Built using React Native, Flutter, or modern web frontends to provide a seamless user interface across all consumer devices.
- API Gateway Layer: Handles critical peripheral tasks such as rate limiting, IAM (Identity and Access Management), threat detection, and intelligent request routing.
- User & Identity Domain: Manages decentralized profile authentication, multi-factor authorization, biometrics, and multi-tenant operational states across consumer and enterprise accounts.
- Policy Engine Domain: Handles highly structured relational matrices defining coverage thresholds, riders, premium structures, rules, and localized tax configurations.
- Claims Processing Domain: An asynchronous workflow engine that ingests incident metadata, handles structured damage logs, orchestrates manual or automated adjustments, and manages financial payout pipelines.
- Telematics Data Ingestion Pipeline: A high-throughput, low-latency ingestion framework optimized to receive continuous streams of location, speed, or biometric events from external edge devices.
- Secure Auditing Engine: An unalterable transaction ledger that logs every modification to policy states, claims adjustment updates, and automated payouts to ensure bulletproof compliance.
Core Technology Stack Selection for 2026
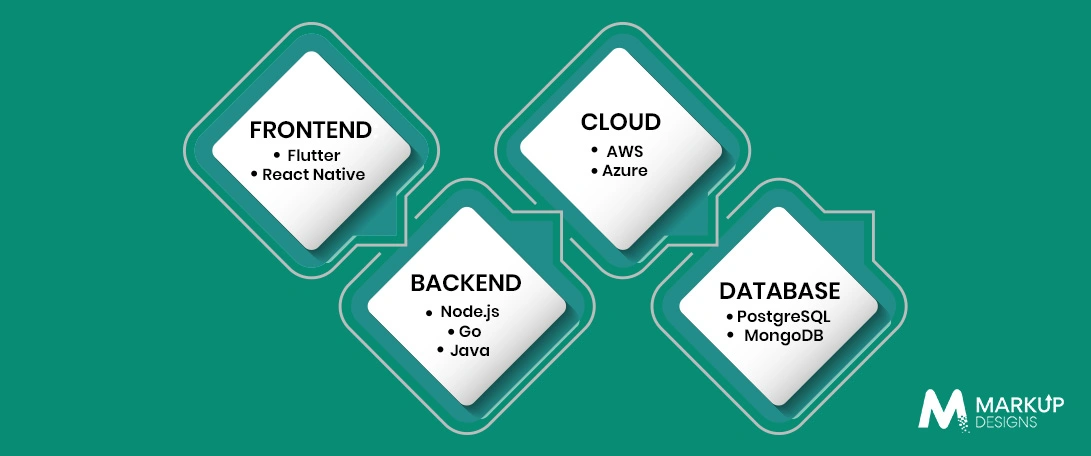
Before launching into product construction, your engineering organization must lock down a production-grade technology stack designed for high concurrency, extensive security, and horizontal scalability. Choosing inappropriate tools at this phase will create massive technical debt and performance bottlenecks.
Backend Development and Microservices Orchestration
For the core business logic and heavy microservices layers, languages and runtimes must be chosen for their ability to run highly concurrent processes with strict memory safety.
- Go (Golang): Highly suited for building the primary API gateways and high-throughput data processing microservices due to its native concurrency primitives (goroutines) and extremely low memory footprint.
- Node.js with TypeScript: Provides an excellent, highly flexible runtime for building customer-facing composition layers and internal orchestration services, matching fast feature delivery with robust type safety.
- Java Spring Boot: Often deployed in enterprise InsurTech environments to build the core transactional accounting pipelines that require mature connection pooling and deep integrations into legacy mainframes.
The Specialized Multi-Database Architecture
An insurance app cannot rely on a single database type. Different domains require distinct data structures and storage optimizations
Relational systems like PostgreSQL handle ACID-compliant, structured core business data, including policy mappings, user accounts, financial records, and cryptographic audit logs.
NoSQL setups like Apache Cassandra or MongoDB manage massive volumes of unstructured and semi-structured documents, including deep claims forms, historical adjuster logs, and variable risk profiles.
For connected vehicle sensors or wearable smart devices, time-series engines like InfluxDB or TimescaleDB ingest and process millions of raw sequential telemetry data points pouring in from connected edge points.
Frontend Application Strategy
To execute high-feature delivery speeds across iOS, Android, and web targets, cross-platform UI frameworks like Flutter or React Native are exceptionally powerful. They allow your engineering teams to maintain a singular, highly testable codebase for core business logic, validation rules, and client state management.
At the same time, this strategy allows you to dip down into native platform channels whenever you need hardware-level access to high-resolution cameras for claim image captures, secure local biometrics, or on-device sensor tracking.
Engineering the Core Modules: A Step-by-Step Guide
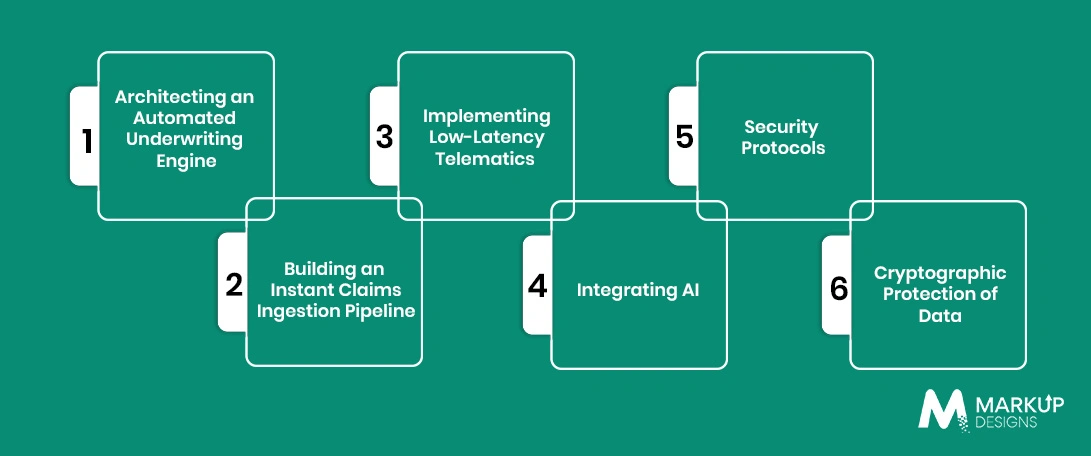
Step 1: Architecting an Automated Underwriting Engine
The foundation of a premium modern insurance application is its ability to price risk dynamically and generate instant policy quotes. Traditional systems require days of manual processing; an enterprise-grade InsurTech application handles this via an asynchronous rules engine.
When a user submits a request for a dynamic quote, the system must pull data from a variety of sources: user demographic data, historical claims databases, external credit check APIs, and real-time risk maps (such as flood plain indexes or local crime statistics).
To prevent blocking your primary client thread, these input parameters are pushed onto an asynchronous worker pool. The application executes a chain of highly optimized mathematical validations to compute an individual risk score, dynamically binding a premium price against specific coverage limits.
By caching common regional risk parameters inside an in-memory Redis layer, your system can return finalized coverage quotes in less than two seconds, maximizing customer conversion rates.
Step 2: Building an Instant Claims Ingestion Pipeline
The claims module represents the most transactional, high-write portion of the entire application. When an accident or loss event occurs, the client application must capture a heavy load of multimedia assets (high-resolution images, videos, and geolocated timestamps) along with unstructured text strings detailing the incident.
To handle this smoothly under heavy network loads, the client application routes data through an API gateway, which pushes the initial payload metadata into a distributed ingestion queue like Apache Kafka or RabbitMQ. This decouples the file upload process entirely from the main transactional backend database.
The heavy multimedia files are pushed directly into a secure, encrypted Object Storage bucket (such as AWS S3 or Google Cloud Storage) using secure, pre-signed upload URLs generated on the fly. Concurrently, a background worker consumes the event from the queue, links the storage paths to the user’s primary relational database record, and kicks off the automated review process.
Step 3: Implementing Low-Latency Telematics and IoT Ingestion
For usage-based insurance products (such as “pay-how-you-drive” auto policies), the application must regularly ingest continuous streams of sequential GPS, velocity, and accelerometer data. Pushing millions of raw telemetry rows straight into a traditional transactional database like
PostgreSQL will completely degrade application performance.
Instead, execute your telematics streaming path using specialized time-series data engines. The mobile device runs an optimized background service that batches telemetry points locally, compressing the data array to save battery life. It then transmits these compressed data packets down an authenticated, low-overhead endpoint at fixed intervals.
An ingestion layer running Apache Kafka captures these streams, pushes them into a time-series datastore like TimescaleDB, and runs analytics workers to flag dangerous driving events (such as hard braking or excessive speeding). The system updates the user’s ongoing safety profile and dynamically adjusts their next billing cycle premium.
Step 4: Integrating AI and Automated Document Parsing (OCR)
Manual verification of medical invoices, repair shop bills, and identity documents represents a massive operational bottleneck. Modern insurance app architecture solves this by integrating intelligent Document Processing (IDP) directly into the file pipeline.
As soon as a claim document lands in your object storage layer, a background event notification fires a serverless microservice function. This service forwards the asset to an advanced Optical Character Recognition (OCR) pipeline. The engine strips the text layout, verifies structural elements (such as tax IDs, medical codes, and cross-total matching), and extracts key figures into a clean JSON structure.
This structured output is then cross-referenced against the policy definitions to catch errors, identify fraudulent claims duplication patterns, and auto-approve claims that sit safely beneath defined monetary risk limits.
Security Protocols and Regulatory Compliance
Because insurance applications collect and process highly confidential personal information, including medical histories, financial records, residential tracking data, and official identity documents, they are primary targets for malicious actors. Your architecture must be designed from day one to enforce absolute defense-in-depth security principles.
Cryptographic Protection of Data Elements
Data must be protected at every single stage of its lifecycle. All data moving across network layers must use TLS 1.3 transport security.
Inside your database tables, all personally identifiable information (PII) must be encrypted at rest using strong AES-GCM-256 cryptographic keys managed by a dedicated, hardware-backed Key Management Service (KMS). Keys must be rotated automatically on a regular schedule, and access to decryption processes must be limited strictly to authorized service layers.
Data Architecture and Long-Term Scalability
As an InsurTech platform scales over time, it generates massive volumes of long-term data. Millions of policy documents, billions of fine-grained telematics points, and petabytes of accident imagery can easily overwhelm your database clusters and drive hosting costs out of control. To maintain high responsiveness and manage infrastructure expenses, your engineering team must deploy proactive database optimization patterns.
1. Database Sharding and Horizontal Partitioning
To prevent a single-core database cluster from becoming a structural bottleneck, your relational storage architecture should be horizontally sharded. For global or enterprise platforms, partitioning your primary tables by geographic country code or region ID ensures that workloads are balanced cleanly across independent database clusters.
Within individual regional databases, heavy tables like claims_history and premium_payments should utilize monthly range partitioning. This optimization ensures that your active application queries scan tiny, highly indexed tables rather than chugging through billions of legacy rows.
2. High-Performance Data Tiering and Archival Strategy
Not all data requires identical access speeds. To keep operational costs lean while preserving analytical capabilities, your system should enforce a clear data tiering strategy based on record age and activity metrics:
- Hot Tier (High Availability): Active policies, unresolved claims, and current-month financial records sit inside your main relational database and high-speed memory caches for sub-second retrieval.
- Warm Tier (Analytical Access): Historical claims records older than six months are systematically offloaded to an enterprise data lake engine like Snowflake or AWS Athena. This allows compliance teams and actuarial analysts to run heavy, cross-cutting risk queries without degrading the live transitional database.
- Cold Tier (Deep Archival): Settled policies and closed claims files from previous years are compressed and pushed into automated cold object storage (such as AWS Glacier Deep Archive). This fulfills statutory data retention laws for less than a fraction of hot tier hosting costs.
3. Asynchronous Multimedia Optimization
When users upload high-resolution images of car damage or property incidents, storing raw, multi-megabyte DSLR or smartphone images directly to long-term cloud buckets creates a huge, expensive storage burden.
Your application pipeline must process all media uploads through an automated asset optimization microservice. As soon as a file upload is completed, a serverless background worker pulls the asset, strips out non-essential metadata headers, converts the format to an efficient modern standard like WebP or AVIF, and resizes the image to optimized resolutions. This process reduces long-term media storage costs by up to 65% while speeding up image rendering times on mobile devices.
Partnering with Markup Designs
Navigating the complexities of enterprise InsurTech development requires more than just standard software implementation; it demands deep architectural expertise in building resilient, highly concurrent, and regulatory-compliant digital systems. At Markup Designs, we specialize in engineering production-grade real-time systems, cloud-native backend infrastructures, and highly optimized cross-platform interfaces tailored explicitly to the needs of modern insurance enterprises.
Our engineering teams work side-by-side with your product organization to deploy reliable database sharding models, low-latency telematics ingestion engines, automated document processing modules, and robust zero-trust security frameworks. By mitigating technical debt and prioritizing architecture built for long-term horizontal scale, we turn complex technical challenges into distinct operational advantages, enabling your platform to handle millions of simultaneous transactions with ease.
Empower Your Product with Production-Grade Architecture
Build highly concurrent, beautifully optimized, and deeply secure insurance ecosystems engineered for global scale, absolute compliance, and rock-solid performance. Turn your vision into an industry-leading financial ecosystem.

Conclusion
Building an enterprise-ready insurance application requires moving past traditional web development models and stepping directly into the world of highly concurrent distributed systems engineering. Success requires balancing a secure, zero-trust backend framework with robust event ingestion pipelines, smart multi-database indexing strategies, and highly responsive, offline-first client architectures.
From localized niche micro-insurance coverages to sprawling corporate risk management networks, digital insurance tools are fundamentally changing how the modern world evaluates and handles risk. Today, features like instant automated underwriting, zero-friction telematics tracking, and intelligent automated claims document parsing are no longer premium additions; they are baseline functional requirements for any serious market launch. The software engineering organizations that will lead the InsurTech space tomorrow are those that view their mobile platforms not as simple frontends, but as deep, resilient, and highly secure infrastructure built explicitly to handle seamless real-time human risk mitigation.
FAQ’s
1. What is the primary operational bottleneck when scaling an insurance application?
The biggest challenge is managing high-throughput, write-heavy data ingestion workloads, such as telematics streaming and multi-media asset uploads, without slowing down core transactional processes like policy lookups and billing runs. Deploying asynchronous event queues like Apache Kafka separates these intensive input operations from the main relational database.
2. Why are standard, single-database setups a poor fit for modern InsurTech?
Insurance applications handle wildly diverse data types. Relational data (user accounts and policies) requires strict ACID compliance, transactional histories require immutable logging, telematics needs high-volume time-series storage, and claims require flexible document structures. A multi-database architecture matching individual database engines to specific data domains is vital for long-term scalability.
3. How does usage-based insurance telemetry ingest data without killing mobile batteries?
The mobile app runs an optimized background service that buffers sensor points locally on the device, stripping out duplicate coordinates and minor noise. It compresses the data packet array and uploads it to the backend server in batches at fixed intervals rather than establishing a continuous stream, which preserves device battery life.
4. How do bitwise operations optimize permissions within broker systems?
Bitwise permission systems turn complex, nested arrays of role access definitions into a single, compact integer value. This allows your backend services to check intricate, multi-layered authorization checks using high-speed mathematical CPU operations, keeping your core API routes running at lightning speed under heavy peak loads.
5. Can automated OCR document parsing entirely replace human claims adjusters?
No. While automated OCR and machine learning engines can parse invoices, extract structural values, and auto-approve small, low-risk claims that fall beneath preset monetary thresholds, their primary role is operational acceleration. High-value claims, complex legal disputes, and anomalies flagged by fraud detection models are automatically routed to human adjusters for final evaluation.
6. How can an insurance application guarantee zero-lag performance during heavy traffic?
By decoupling your real-time network layer entirely from visual presentation logic, using virtualized list processing to render only visible elements within the UI viewport, and deploying predictive offline caching stores so the app stays functional even without an active internet connection.
Author's Perspective
Many development teams still approach modern InsurTech platforms as if they were simple extensions of traditional CRUD (Create, Read, Update, Delete) web applications. In our view, that approach misses the core technical realities of modern digital architecture. High-performance insurance ecosystems have transformed into massive distributed data management networks that require specialized architectural design from day one.
As global user expectations settle firmly on instant communication, dynamic pricing, and immediate claims verification, engineering teams can no longer get away with throwing together basic, unoptimized database loops or uncached transactional layers. True competitive advantage belongs to software organizations that treat their real-time platforms as foundational infrastructure, investing heavily in resilient edge gateways, highly optimized data streams, and ultra-fast client rendering logic. Taking the time to properly engineer these underlying core systems is exactly what separates a crashing prototype from a world-class digital ecosystem.
Discuss Your Project NowJupinder Singh Arora
Founder and CEO
Related Posts

How to Build an EdTech App in Australia...

How to Build an AI-Powered Mobile App in...

How to Hire Mobile App Developers in Kuwait...
Insights Are Valuable & Execution is Priceless
You’ve read about the digital future. Now, let’s build the infrastructure to take you there. Move your strategy from the page to the product.
Design Your Solution Now
Contact Us
Schedule The Appointment At Your Convenience Date And Time.
30 Min
Web Conference
Time Zone
Indian standard time (08:30pm)

Thanks For Getting In Touch!
You’ve Taken The First Step Toward Transforming Your Digital Presence. Our Experts Will Reach Out Shortly To Take It Forward.
Launch Your Dream Project
Provide a brief overview of your project, and our specialists will evaluate your requirements. We will connect with you to explore how the right digital solutions can help you launch faster.